




Retail

Healthcare

Logistics

Manufacturing

Finance

Intelligent Document Processing Using RPA for a North American Retail Giant
Using KingswaySoft, a third-party SSIS integration tool, for both data transfer from an Amazon S3 bucket and hashing sensitive customer information (email addresses and mobile numbers) column by column.
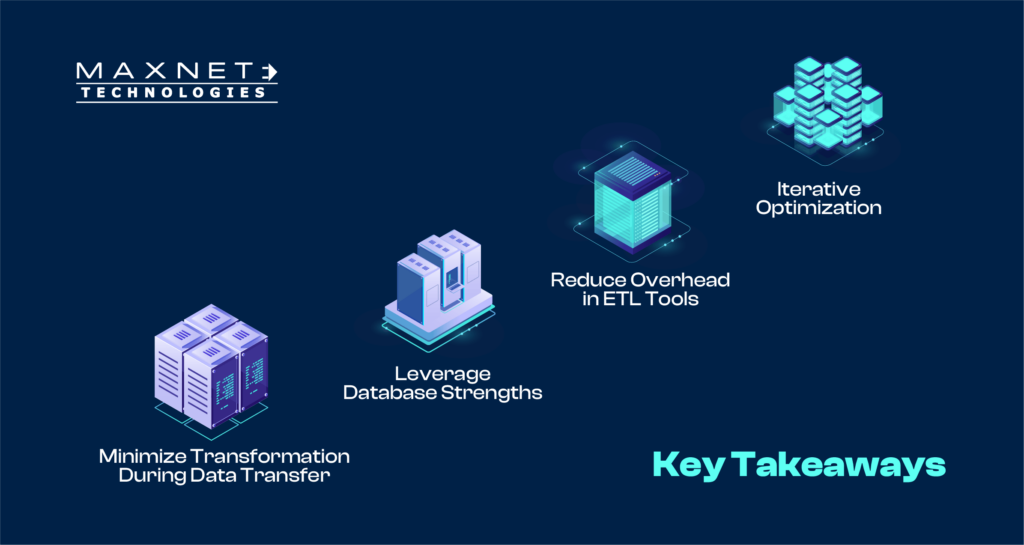
Detailed Use Case for Database Performance Improvement: Optimizing CSV Data Load from Amazon S3
Using KingswaySoft, a third-party SSIS integration tool, for both data transfer from an Amazon S3 bucket and hashing sensitive customer information (email addresses and mobile numbers) column by column.
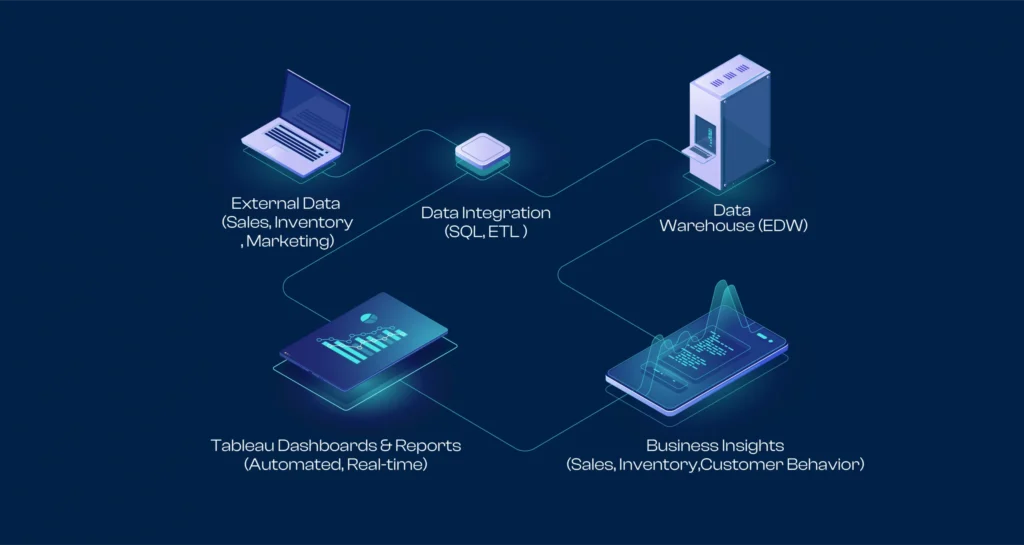
Optimizing Retail Intelligence and Data Management for a Renowned Lighting Solutions Provider with Maxnet
A leading high-quality lighting solutions manufacturer, faced challenges in managing and analyzing vast amounts of data scattered across different systems.
✔︎ Modern Technology
✔︎ IT services






